Якщо у вас є сайт з великим обсягом трафіку, то з поняттям семплювання даних ви швидше за все зіткнетеся, або вже зіткнулися.
Google Analytics визначає семплювання даних як аналіз підмножини даних з метою виявити значну інформацію у більшому наборі даних.
Тобто, коли даних багато, а саме 500 тис. сеансів на рівні ресурсу для діапазону дат, що використовується, то для зниження навантаження на сервер, а також прискорення обробки даних і формування звіту, Google Analytics замість того щоб показувати нам необроблені (сирі) дані бере вибірку з цих даних і прогнозує, добудовує решту маси даних виходячи з аналізу цієї вибірки.
Помітити це явище ми можемо, коли переглядаємо дані на вищому (стандартному для Analytics) рівні, а потім спускаємося на рівень нижче і дані там вже зовсім інші. Наприклад, коли аналізуємо показники на рівні джерел трафіку, бачимо певну кількість конверсій з Google реклами, а потім переходимо на рівень кампаній з цього ж Google/cpc, а сума конверсій по кампаніям вже не сходиться з цифрою, яку ми бачили на рівні джерел.
Google Analytics не застосовує семплювання до стандартних звітів за замовчанням і видає нам необроблені дані в таких звітах. Але якщо ми якимось чином змінимо стандартний звіт, то дані за необхідної кількості сеансів вже будуть обробленими, і від реальних можуть відрізнятися.
Індикатор того, які дані ви переглядаєте - семпльовані чи ні - служить знак праворуч від назви звіту. Якщо вона зелена, то дані "сирі", тобто необроблені, повні. Якщо ж він жовтий, то дані семпльовані.
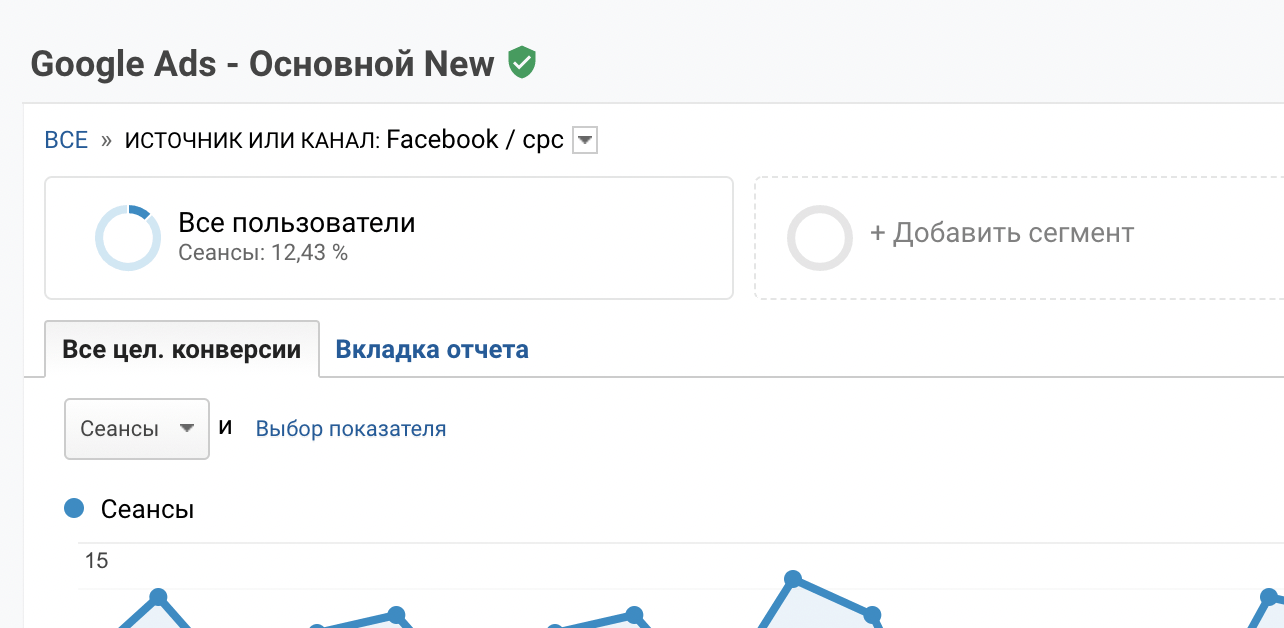
Давайте на прикладі реального проекту розберемо чим може бути небезпечним семплювання даних.
Тематика - Туристичні послуги
Географія - Україна
Інструменти - Google Ads
В одного з наших клієнтів обсяг трафіку на сайті досить великий, як і рекламного трафіку. Тематика – туристичні послуги. Тому ми зіткнулися з обмеженнями Google Analytics.
На основі звітів з Google Analytics ми оцінювали результат, а також орієнтувалися під час оптимізації. Рекламні кампанії поділені за напрямками з різними обсягами трафіку. І якщо у випадку з об'ємними напрямками, де трафіку відносно багато та Google Analytics вистачало даних для “якісного” семплювання, тобто оброблені звіти приблизно сходилися з реальними, то у випадку з дрібнішими напрямками дані сильно відрізнялися.
Що ж робити в такій ситуації, як отримати доступ до "сирих" даних? Ось деякі з варіантів:
- зменшити період звіту. Все логічно: період менший, даних менше, дані не обробляються. Але такий варіант підходить явно не завжди;
- використовувати Google Analytics 360. У такому разі поріг сеансів вільних від семплювання зростає до 100 млн. за вибраний період. Але цей інструмент платний;
- підключити сторонній сервіс та вивантажувати з Google Analytics необроблені дані.
Ось про останній варіант і поговоримо. Сервісів є кілька, але ми зупинимося напевно на найпростішому. Та й підтримка Google Analytics рекомендує використовувати саме цей спосіб, звичайно, неофіційно.
Сервіс називається Supermetrics. Призначений він для імпорту маркетингових даних до Google Sheets. Більш детально про те, як використовувати цей сервіс тут. Сервіс платний, але є тестовий період.
Давайте подивимося, як все виглядає на ділі.
Ось таку кількість транзакцій (цільових дій на сайті) ми бачимо з Google/cpc в липні, коли дивимося стандартний (незмінений) звіт. Значок у назві зелений, отже, дані "сирі”.
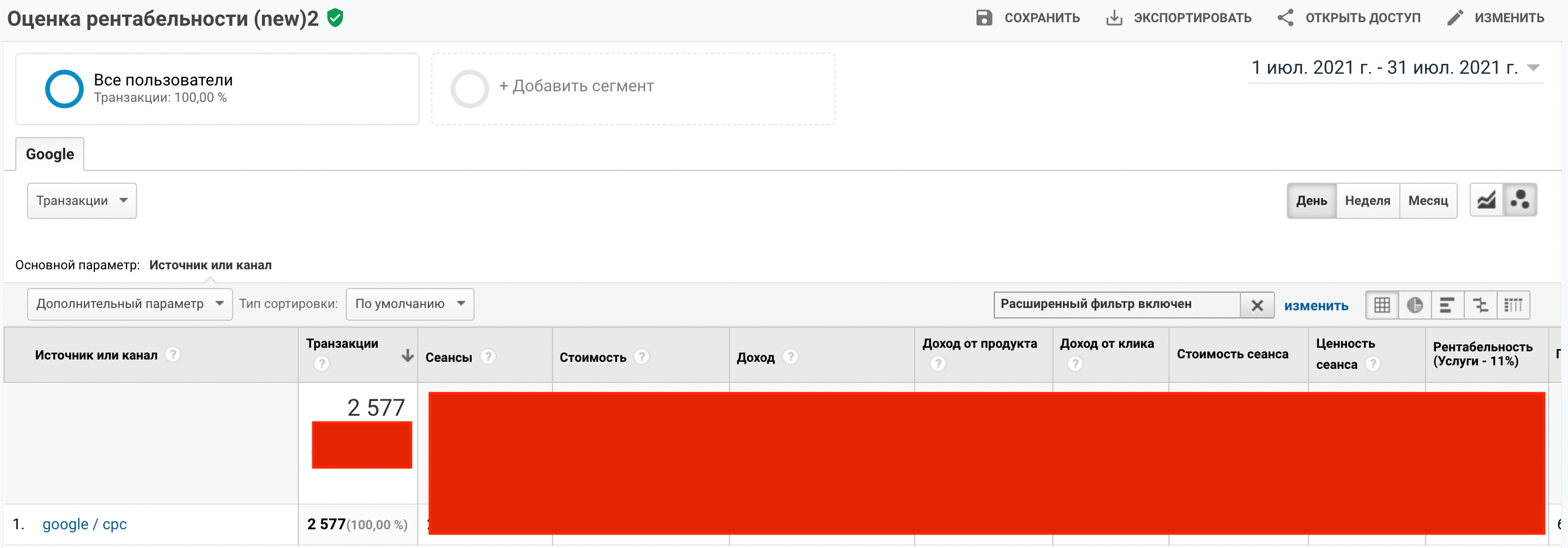
Але як тільки ми хочемо подивитися ту ж статистику щодо Google/cpc, тільки в розрізі кампаній, кількість транзакцій вже інша. І значок, як бачите, жовтий, тобто оброблені дані. І реальної кількості транзакцій з кожної окремої кампанії ми не побачимо. І як уже писали вище, для кампаній з невеликим обсягом трафіку різниця в транзакціях може бути дуже відчутною.
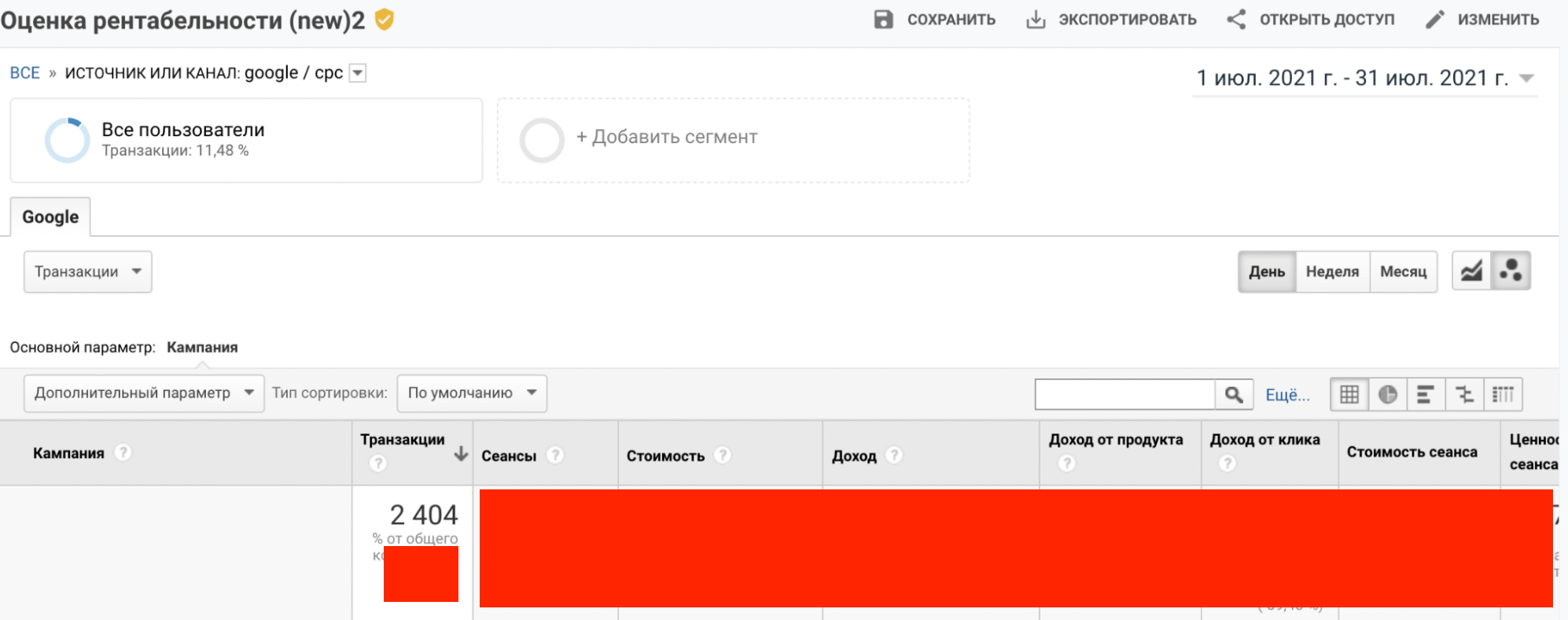
Ось що вийшло після розвантаження даних за допомогою стороннього сервісу. Як бачите, є дані в розрізі кампаній, а сума транзакцій сходитися з "сирими" даними з Google Analytics.
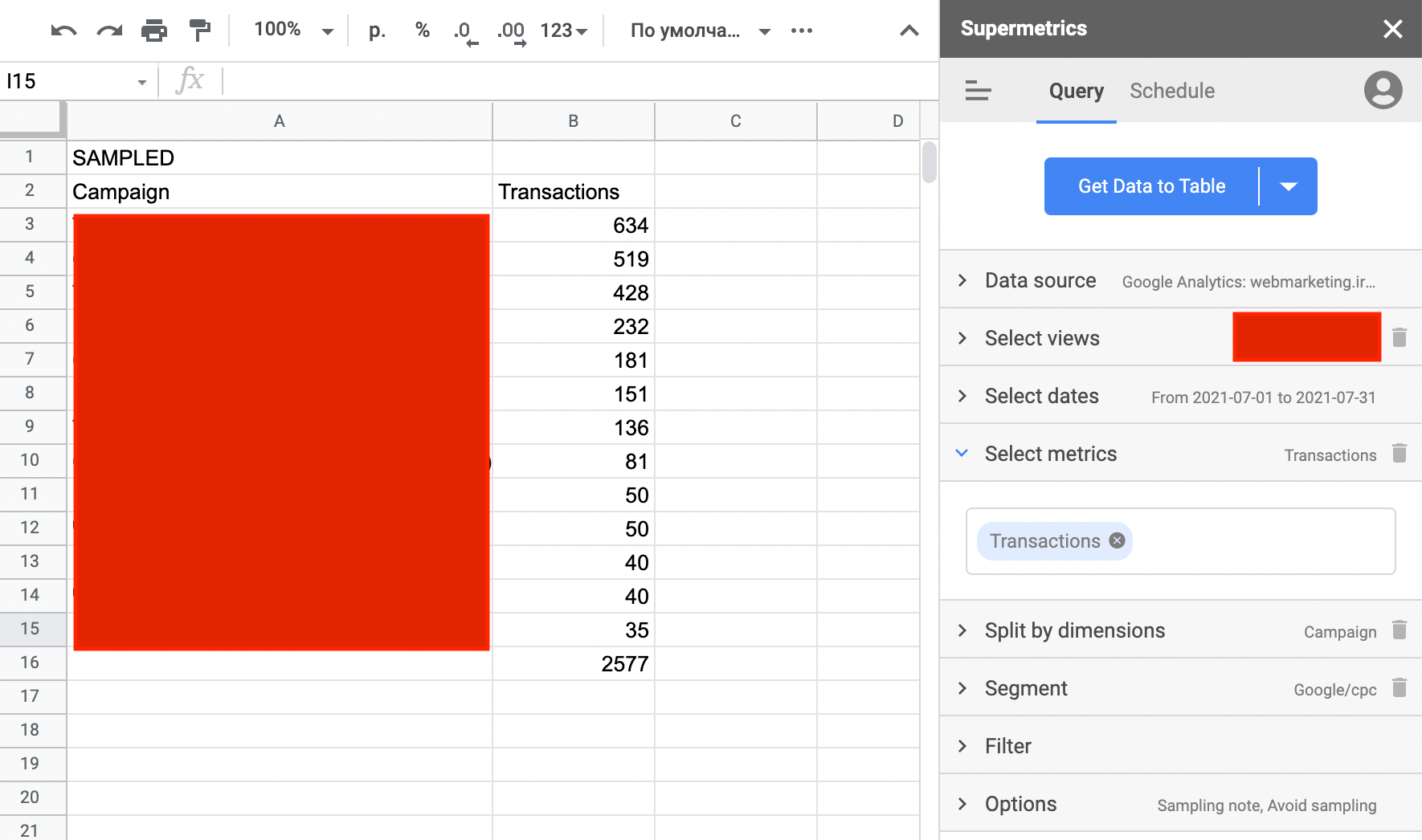
Часто дуже важливо працювати саме з “сирими” даними, але, на жаль, у Google Analytics є обмеження щодо цього. Добре, що є способи дістати ці дані. Що стосується саме Supermetrics, цей спосіб можна швидко впровадити, він не складний, але порівняно не автоматизований і працювати надалі з даними може бути не зовсім зручно.

